
内存对齐
在了解内存对齐这个概念之前,我们首先要知道的是32位系统,一次能最大处理的位数,即取出的数据最多为32位,即4个字节,内存对齐的话就是4字节的内存对齐,如果是64位系统,则同理得出是8字节内存对齐。
注:以下内容和代码部分选自其他文章。
知道了上述前提后,我们要清楚内存中数据存放的形式是怎么样的?如果以大体图来解释的话,如下:

所以针对上述对32位和64位系统的解释,我们可以看出,针对32位系统,每4字节的数据放在一起,每次取也是4字节一起取。
为什么需要内存对齐?
- 平台问题:并不是所有的硬件平台都能访问任意地址上的任意数据。有些CPU可以访问任意地址上的任意数据,而有些CPU只能在特定地址访问数据,因此不同硬件平台具有差异性,这样的代码就不具有移植性,如果在编译时,将分配的内存进行对齐,这就具有平台可以移植性了。
- 性能问题:访问未对齐内存需要cpu进行两次访问,对齐后只需要一次。CPU访问内存时并不是逐个字节访问,而是以字长(word size)为单位访问,例如 32位的CPU字长是4字节,64位的是8字节。如果变量的地址没有对齐,可能需要多次访问才能完整读取到变量内容,而对齐后可能就只需要一次内存访问,因此内存对齐可以减少CPU访问内存的次数,加大CPU访问内存的吞吐量。
内存对齐的概念
所以基于以上原因,理论上计算机可以访问任意地址的变量,但是在访问特定类型通常在特定的内存地址中,数据存放并不是随意存放,从上面的图可以得出,是有规则的顺序,我们能够分析出,内存对齐是为了能够快速访问内存进行数据的存取,但是会消耗内存空间,用空间换时间的一种内存存储规则。
Go语言中内存对齐的体现
首先看一下下面这段代码:
|
|
是不是对这个结果有疑问呢?为什么s1和s2的数据长度不同,但是打印出的内存长度一样?为什么t1和t2的结构体只是定义的顺序不同,内存长度却不一样?
这里要说明一下,go语言通过unsafe.Sizeof(x)打印的变量占用的内存字节数,和底层数据无关,不包含x所指向的内容大小,所以第一个疑问解决了。也同理我们可以通过unsafe.Sizeof()打印出各个类型的内存占用大小。
注:这里使用的是64位系统。
| 类型 | 字节数 |
|---|---|
| bool | 1 |
| intN, uintN, floatN, complexN | N/8 个字节 (int32 是 4 个字节) |
| int, uint, uintptr | 计算机字长/8 (64位 是 8 个字节) |
| *T, map, func, chan | 计算机字长/8 (64位 是 8 个字节) |
| string (data、len) | 2 * 计算机字长/8 (64位 是 16 个字节) |
| interface (tab、data 或 _type、data) | 2 * 计算机字长/8 (64位 是 16 个字节) |
| []T (array、len、cap) | 3 * 计算机字长/8 (64位 是 24 个字节) |
接下来,我们针对结构体的疑惑来讨论,在文章的开头我们已经介绍过,数据在内存中存放的形式。在如下结构体中:
|
|
对于上面的结构,如果是没有进行过内存对齐,则按照存放的顺序,以32位系统的每4个字节取数据的规则,会发现除了a,b和c都不是从头取的,过程如图:
这里就有一个问题,对于b和c没有做到从起始位开始取数据,所以会造成之后在再次拼接整理的操作,需要多次内存访问和整理的步骤。而如果经过内存对齐,就会如图:
所以我们能发现,内存对齐减少了操作步骤,但是缺浪费了内存空间占用的资源。
内存对齐的规则
在介绍规则前,go语言unsafe包下还有另外两个函数,unsafe.Alignof()和unsafe.Offsetof(),他们分别是可以获取对齐值和偏移量。这里也介绍一下。
unsafe.Alignof()
unsafe.Alignof()接受任何类型的表达式,并返回其对齐方式,在结构体中返回的是对应类型字段所需的对齐方式。
- 对于struct结构体,计算每一个
unsafe.Alignof(x.f),unsafe.Alignof(x)是其最大值。 - 对于array数组,
unsafe.Alignof(x)等于构成数组的元素类型的对齐倍数。 - 对于基础类型,
unsafe.Alignof(x)返回为min(字长/8,unsafe.Sizeof(x)),即计算机字长与类型占用内存的较小值。
|
|
unsafe.Offsetof()
知道了每个类型的规则后,就可以使用unsafe.Offsetof()计算结构体内类型的偏移量,官方注释中也说明,which must be of the form structValue.field,所以只有在类型是结构体是才有意义。
|
|
可能对于这个偏移量的计算结果有些疑惑,这个unsafe.Offsetof()其实就是在内存对齐之后计算出来的偏移量,即计算特定的地址了,所以这一步需要先看规则。
内存对齐规则
- 成员对齐规则:针对一个基础类型变量,如果
unsafe.AlignOf()返回的值是m,那么该变量的地址需要被m整除(如果当前地址不能整除,填充空白字节,直至可以整除)。 - 整体对齐规则:针对一个结构体,如果
unsafe.AlignOf()返回值是m,需要保证该结构体整体内存占用是m的整数倍,如果当前不是整数倍,需要在后面填充空白字节。
针对该规则,我们再把上述的结构体和unsafe.Offsetof()拿出来分析一下:
|
|
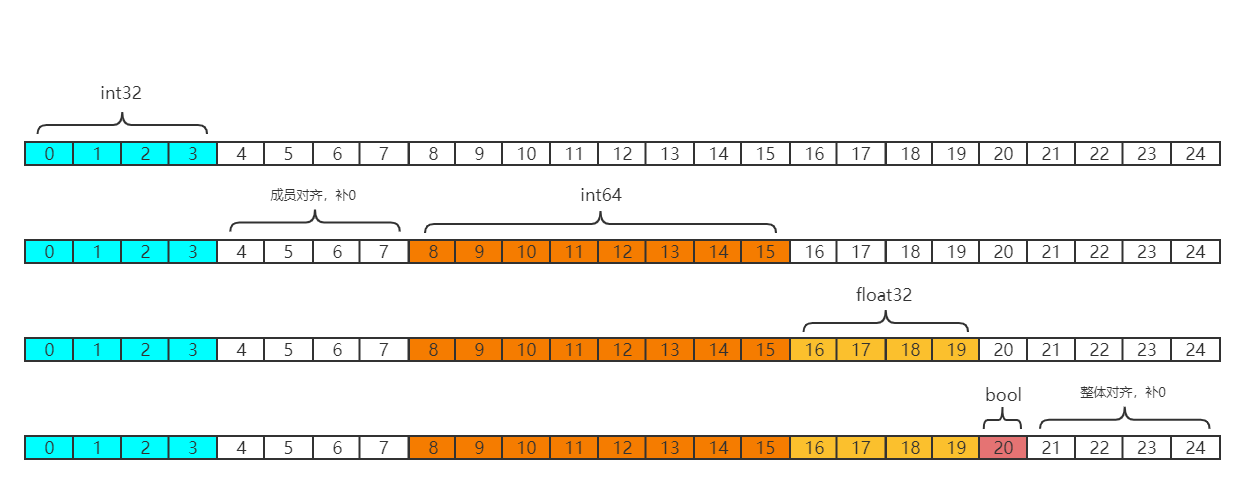
有一点需要注意,就是如果结构体内部嵌入了空结构体,那么当空结构体位于结构体的前面和中间位置,并不会占用内存,如果是末尾的话,需要内存对齐,占用的空间和前一个变量保持一致。
|
|
OK!以上就是内存对齐的介绍了,从上面的介绍可以看出,在开发过程中,我们可以调整结构体内变量的位置来优化内存占用。
Life is fantastic !