Map
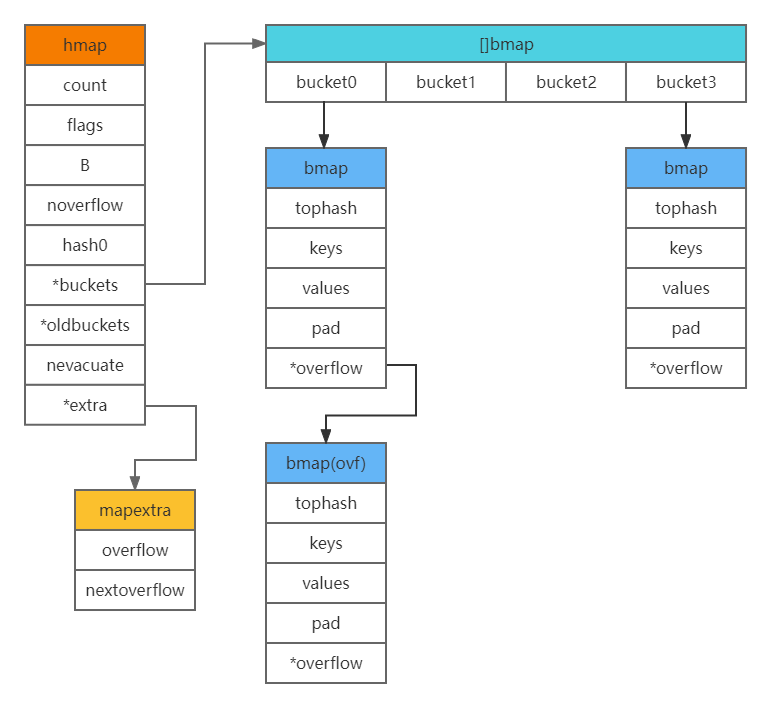
Map是go语言的一种数据结构,它是一种无序的键值对集合。go语言的map是使用hashmap实现的。使用数组+链表的形式,用拉链法消除hash冲突。go语言中的map主要是由两种结构组成,hmap和bmap。
以下结构内容和代码选自其他文章。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
type hmap struct {
count int //元素个数,调用len(map)时直接返回
flags uint8 //标志map当前状态,正在删除元素、添加元素.....
B uint8 //单元(buckets)的对数 B=5表示能容纳32个元素
noverflow uint16 //单元(buckets)溢出数量,如果一个单元能存8个key,此时存储了9个,溢出了,就需要再增加一个单元
hash0 uint32 //哈希种子
buckets unsafe.Pointer //指向单元(buckets)数组,大小为2^B,可以为nil
oldbuckets unsafe.Pointer //扩容的时候,buckets长度会是oldbuckets的两倍
nevacute uintptr //指示扩容进度,小于此buckets迁移完成
extra *mapextra //与gc相关 可选字段
}
//a bucket for a Go map
type bmap struct {
tophash [bucketCnt]uint8
}
//实际上编辑期间会动态生成一个新的结构体
type bmap struct {
topbits [8]uint8 // 高位哈希值
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr // 指向扩容后的bucket
}
|
由上面的结构可知,key和value都存在bmap中,且不是以指针形式,最多存放8个,key存放位置由高位哈希值决定,低位哈希值用于选择把kv存放在bmap数组中的哪一个里。具体为在存储key时不能重复,如果key重复,value会进行覆盖,通过key进行哈希运算,然后进行计算得到位置,但是这样会出现哈希冲突的问题,go语言的解决方法是用拉链法解决哈希冲突,也就是用链表,在冲突位置的元素上形成一个链表,通过指针互连接,在查找的时候如果发现key冲突了,会顺着链表一直向下找,直到尾节点,找不到则返回空。
overflow指针指向的是扩容后的下一个bmap,会把overflow指针存到extra中。
1
2
3
4
5
6
7
8
|
type mapextra struct {
// overflow[0] contains overflow buckets for hmap.buckets.
// overflow[1] contains overflow buckets for hmap.oldbuckets.
overflow [2]*[]*bmap
// nextOverflow 包含空闲的 overflow bucket,这是预分配的 bucket
nextOverflow *bmap
}
|
overflow是一个指针,看结构的定义,在map哈希冲突过多时,会发生扩容,为了不全量搬迁数据,使用增量搬迁,所以按照解释说的,[0]时当前溢出桶的集合,[1]是发生扩容后,保留旧的溢出桶集合,overflow存在的意义在于防止溢出桶被gc。
而bmap的内存模型如下,
1
|
|...|key0|key1|key2|key3|value0|value1|value2|value3|*overflow|
|
可以观察到,key和value并不是键值对的形式存储,是独立分开按照顺寻存放,目的是为了减少pad字段,消除padding(内存对齐)带来的空间浪费。比如:map[int64]int8,如果以key-value的形式存储就必须在每个value后面添加padding7个字节,如果以上述的形式只需要在最后一个value后面添加padding就可以了。
下面是整个map的大体构造:
 接下来简单说一下
接下来简单说一下map的创建函数
1
2
3
4
5
6
7
8
|
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
......
return h
}
|
我们观察到,其实每次make(map[key]value)返回的是指针,而每次复制,比如a := b这种操作,也是创建指针副本,复制了hmap的指针,都是共享一个map,使用起来很像引用,这个和slice的底层数组不同,每次map的扩容,所有都是共享一个map。
下面是go语言中map存储赋值的部分源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
//获取hash算法
alg := t.key.alg
//计算hash值
hash := alg.hash(key, uintptr(h.hash0))
//如果bucket数组一开始为空,则初始化
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// 定位存储在哪一个bucket中
bucket := hash & bucketMask(h.B)
//得到bucket的结构体
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) +bucket*uintptr(t.bucketsize)))
//获取高八位hash值
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
//死循环
for {
//循环bucket中的tophash数组
for i := uintptr(0); i < bucketCnt; i++ {
//如果hash不相等
if b.tophash[i] != top {
//判断是否为空,为空则插入
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add( unsafe.Pointer(b),
dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize) )
}
//插入成功,终止最外层循环
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//到这里说明高八位hash一样,获取已存在的key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
//判断两个key是否相等,不相等就循环下一个
if !alg.equal(key, k) {
continue
}
// 如果相等则更新
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
//获取已存在的value
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
//如果上一个bucket没能插入,则通过overflow获取链表上的下一个bucket
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
if inserti == nil {
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/value at insert position
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key)
//将高八位hash值存储
*inserti = top
h.count++
return val
}
|
有一个地方要注意一下go语言的map,通过key获取到value,value是不可寻址的,因为map会进行动态扩容,进行扩展后,map的value会进行内存迁移,其地址会发生变化,无法对这个value进行寻址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func main() {
type test struct {
t string
}
testmap := make(map[string]test)
testmap["test"] = test{t: "ZonzeeLi"}
// 这一行编译不通过
testmap["test"].t = "Changed"
// 这个不是复制map,不会对原map有影响
p := testmap["test"]
p.t = "Changed again"
}
|
Map的扩缩容机制
map最重要且最多问的就是其扩容机制,这里把扩缩容都简单总结一下。
有两种情况要扩容,一种是kv太多,超过负载,另一种是overflow的bucket过多。第一种情况当扩容时,go语言会将bucket数组的数量扩充一倍,产生一个新的bucket数组,并且将就数组的数据迁移至新数组中,如果是bucket过多,也就是第二种情况,扩容后的bucket数量不变,做内存整理。我们来解释一下扩充的过程,当map的长度增大到大于负载因子所需的长度,会去申请一个新的大数组作为bucket,即 newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil),回将旧的bucket数组存放在oldbucket中做填充,这里并不是立即把旧的数组中的数据转移到新的newbucket中,而是只有在访问到具体的某个bucket时,才会把数据转移到新的newbucket中,如下图:
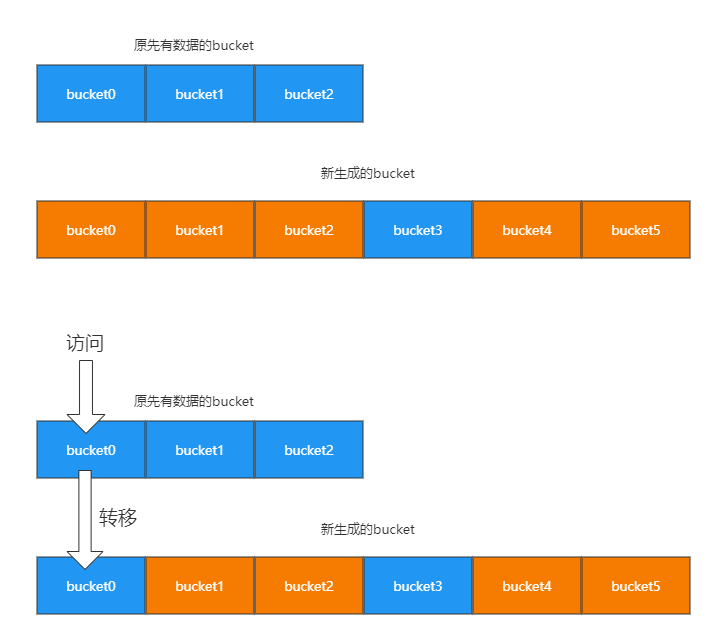 注:这里并不会直接删除旧的
注:这里并不会直接删除旧的bucket,而是把原来的引用去掉,利用gc清除内存。
那么在这里就可以联想到,map的删除操作,如果key是一个指针类型,则将其置空,等待gc清除,如果是值,则清楚相关内存,对value也是相关操作,最后会把key对应的高位值对应的数组index置为空。但是map的delete操作,会有可能出现很多空的kv,会导致搬迁操作。
1
2
3
4
5
6
7
8
|
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
...
}
|
无论是扩容还是缩容,对应的代码段都是这一段,如果是扩容,则bigger = 1,否则容量不变,所以缩容,对于内存空间的占用来说并没有发生改变。所以针对上述介绍的map的delete操作,不注意管理会使分配的内存不断增加。
Map的并发安全问题
go语言的map并不支持并发读写,也就是非线程安全的,这一点和slice真的是难兄难弟。如果有多个goroutine操作,代码写法不当会报错fatal error: concurrent map writes,无论是在读在写的过程中,甚至是写一个http的请求服务,每次都要读一个map,在高并发的场景下也会报这样的错,而在其他时候并不会,所以这是一个隐式问题。那么该如何处理呢?
1
2
3
4
|
var b = struct{
sync.RWMutex
m map[string]int
}{m: make(map[string]int)}
|
最常见的就是加一个锁,定义一个结构体包含一个map结构体和一个嵌入读写锁sync.RWMutex。读写数据分别如下:
1
2
3
4
5
6
7
8
9
|
// 读数据
b.RLock()
a := b.m["test"]
b.RUnlock()
// 写数据
b.Lock()
b.m["test"] ++
b.Unlock()
|
而go语言自身提供了一种type Map,即sync.Map,是一种支持并发读写的map,其中包含两个数据结构read和dirty,减少锁对性能的影响。
1
2
3
4
5
6
|
type Map struct {
mu Mutex
read atomic.Value // readOnly
dirty map[interface{}]*entry
misses int
}
|
1
2
3
4
5
6
|
func (m *Map) Delete(key interface{})
func (m *Map) Load(key interface{}) (value interface{}, ok bool)
func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool)
func (m *Map) LoadOrStore(key, value interface{}) (actual interface{}, loaded bool)
func (m *Map) Range(f func(key, value interface{}) bool)
func (m *Map) Store(key, value interface{})
|
对于sync.Map结构,更适合读多写少的场景,我之前看到了煎鱼大佬对sync.Map内部结构的分析和为什么适合读多写少的性能测试,感兴趣的可以看一下这篇文章。
OK!有关go语言map的介绍就这么多了,至于扩容内部源码的分析、搬迁操作等可以再细致的对应代码去理解。
Coding every day!
